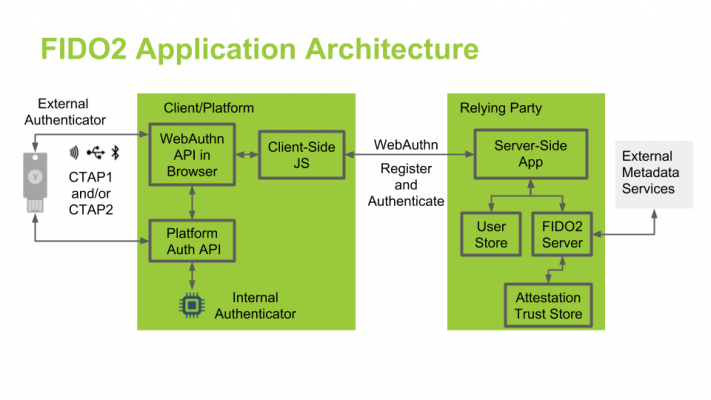
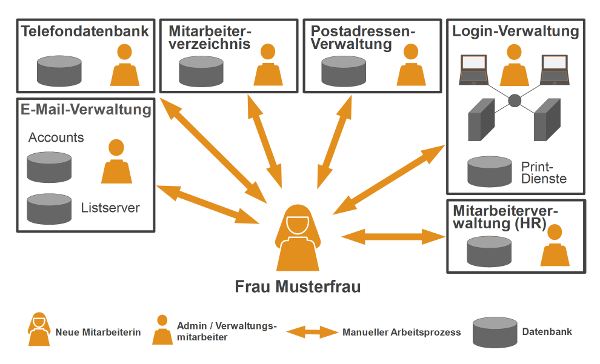
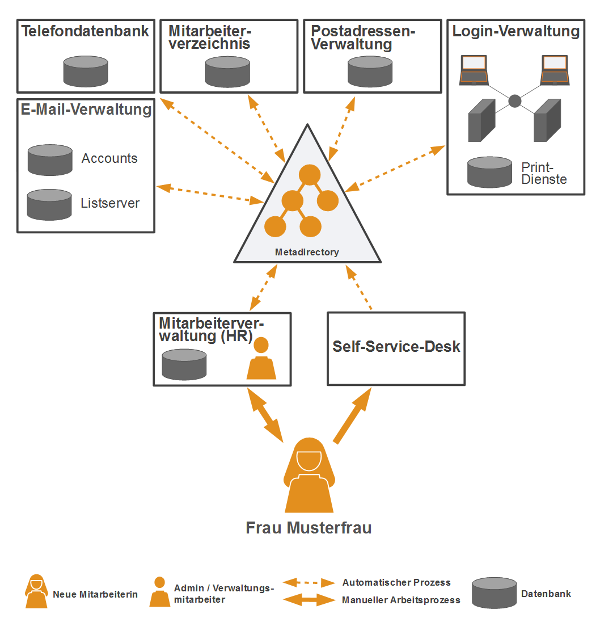
OAuth2 löst das mit Sicherheitsmängeln behaftete OAuth 1.0 ab. Das offene Protokoll wird zur Autorisierung von Ressourcen im Web verwendet und basiert auf etablierten Standards wie HTTP, TLS und JSON. Clients müssen nicht mehr die vertraulichen Daten von Benutzern vorhalten, sondern bekommen vom Authorization Server (AS) der Ressource ein Access-Token, welches sie bei der Ressource vorzeigen, um an die Inhalte zu kommen.
Das Access Token ist zeitlich befristet gültig. Üblicherweise stellt der AS das Access Token zusammen mit einem Refresh Token aus. Endet die Gültigkeit eines Access Tokens, kann mittels des Refresh Tokens ein weiteres Access Token vom AS erlangt werden.
Es sind verschiedene Abläufe vorgesehen:
- Web Server: Zugriff über den Browser auf den Server (Client) und die Ressource
- User Agent: Für Clients (z.B. JavaScript) im Browser
- Native Application: Für Programme in stationären oder mobilen Geräten in Kombination mit einem Browser
- Device: Für Geräte ohne Tastatur. Eingaben werden auf einem zweiten Computer gemacht.
- Client Credentials: Für sichere Client-Service-Verbindungen ohne Benutzerinteraktion
In jedem Fall (außer Client Credentials) erfolgt eine Bestätigung durch den Benutzer, dass der Client autorisiert ist, auf den Service zuzugreifen.
Für die Authentifizierung, d.h. die Feststellung der Identität des Benutzers, wird auf externe Mechanismen verwiesen. Eine mögliche Variante solcher Tokens sind Bearer Tokens: Derjenige, der das Token besitzt, hat alle Rechte daran und muss sich nicht über bestimmte Merkmale, wie z.B. Serverzertifikate, ausweisen.
Bearer Tokens sind die häufigste Token-Form. Besonders hervorzuheben ist hierbei der Einsatz von OpenID Connect, welches direkt aufbauend auf die OAuth2-Spezifikation entwickelt wurde. Andere Methoden, etwa SAML-Assertions, sind ebenso möglich.
Schon seit einer Weile setzten eine Reihe großer Service-Anbieter das Protokoll ein, z.B. Facebook, Google, GitHub, Microsoft, bitly u.a.
Weitere Informationen:
IETF-Seiten zur Standardisierung von OAuth2