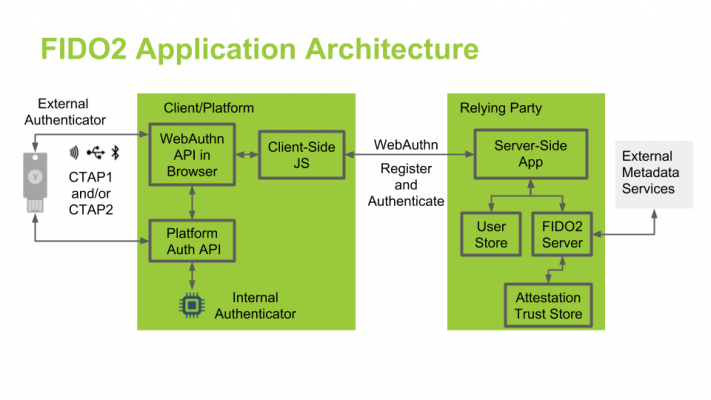
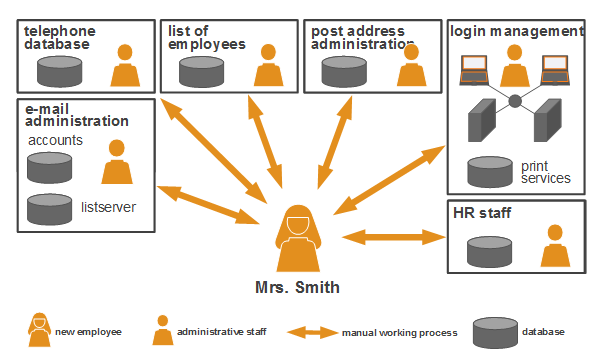
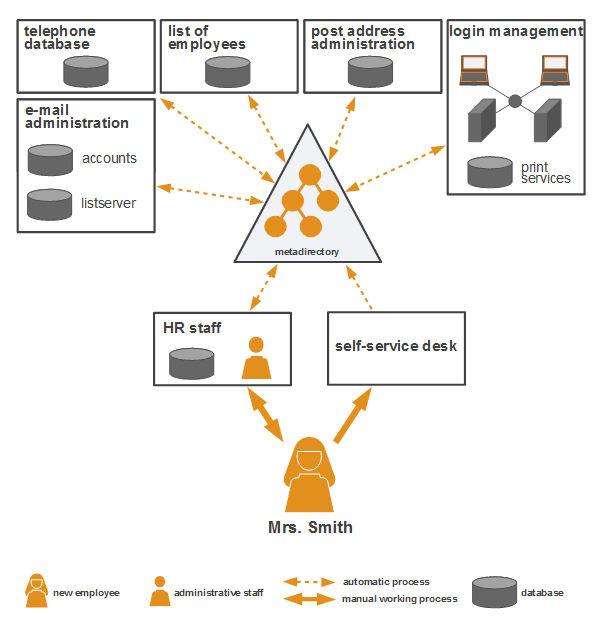
In the RBAC model (Role Based Access Control), users of a system are assigned certain roles. These roles entail different levels of access rights to specific resources. For example, a role “department manager” could provide reading and writing rights for a resource, whereas the role “secretary” only reading rights. Hence, administration is simplified due to rights being assigned along with the respective role of a user. In order to alter a user’s rights, user roles can be added or deleted.
The difference between groups and the in RBAC used roles is less the technical implementation than the organisational use. Thus one could differentiate them as follows:
- Role is a characteristic that determines specific behavioral rules and patterns and is related to specific rights and duties. These are in particular functions within an organisation. Roles can be hierarchically structured, so that the role secretary if located in an organisational unit would only give access rights for the identities in this department
- Group is a much more general concept. The match of only one arbitrary characteristic is enough to define a group, for example „subscriber of mailing list X“.
DAASI International implemented the RBAC standard in their IAm software didmos. Originally, it was used in the module “Decision Point” (longterm clients know it as OpenRBAC). didmos1 Decision Point stores all necessary information (about users, roles, resources, etc.) in an LDAP server, which can speed up authorisation decisions as they can be displayed through an LDAP filter. In didmos 2, the Decision Point was completely rewritten and is now part of didmos 2 Core, so that all didmos 2 modules can use it for authorisation decisions. Since it provides a comprehensive REST API, it can also be used by any other application. In one of the next versions of didmos2, a comprehensive web based administrationinterface for the Decision Point will be provided.
didmos1 Decision Point can be integrated even in already existing systems with directory services, as the directory set-up is completely customisable. The client can decide which data should be stored in which place and in which directory. didmos1 Decision Point is also able to function in accordance with preexisting user administration structures. Applications can then access didmos Decision Point via different interfaces (SOAP, REST, PHP-API, SAML/XACML Check Access), so that the software can be flexibly integrated into a multitude of IT landscapes.
The software was developed within the framework of a graduate thesis which was supervised by DAASI International. DAASI International continues to support and advance the software as ready-for-use RBAC implementation. It is fully open source and published under LGPL-license.
The software was already applied, further developed and adapted to individual requirements in commercial and non-commercial projects. Examples for non-commercial projects are the BMBF research projects, TextGrid, and DARIAH.
Further information: